왜 AI Security가 필요한가
기업의 AI 사용은 단순한 실험 단계를 넘어 업무 자동화, 고객 응대, 개발 지원, 내부 지식 검색, 데이터 분석 등 실제 업무 환경으로 빠르게 확장되고 있습니다.
하지만 AI 사용이 늘어날수록 새로운 보안 리스크도 함께 증가합니다. 사용자가 민감한 데이터를 ChatGPT나 Copilot에 입력할 수 있고, 내부 LLM이나 AI Agent가 기업 데이터와 도구에 접근하는 구조에서는 기존 보안 장비가 보지 못하는 새로운 데이터 흐름이 발생할 수 있습니다.
기존 보안으로 AI 사용을 통제하기 어려운 이유
기존 보안은 주로 웹 접속, 파일 전송, 네트워크 트래픽, 사용자 인증을 중심으로 설계되었습니다. 그러나 AI 환경에서는 사용자의 질문, AI의 응답, 내부 API 호출, AI Agent의 자동화된 동작까지 함께 분석해야 합니다.
AI Gateway 기반 생성형 AI 통제 구조
최근 기업 환경에서는 ChatGPT Enterprise, Microsoft Copilot, Gemini, Claude뿐 아니라 내부 LLM과 AI Agent 환경까지 함께 운영되는 구조가 확대되고 있습니다.
AI Gateway는 이러한 다중 LLM 환경을 하나의 정책 체계로 통합하여 사용자 인증, API 접근 제어, Prompt 검사, 데이터 유출 방지 정책을 중앙에서 관리할 수 있도록 지원합니다.

Netskope One AI Gateway
내부 애플리케이션, AI Agent, LLM Provider 사이의 API 트래픽을 통제하고, 인증, Traffic Management, Audit Log, Content Inspection을 하나의 정책 체계로 관리합니다.
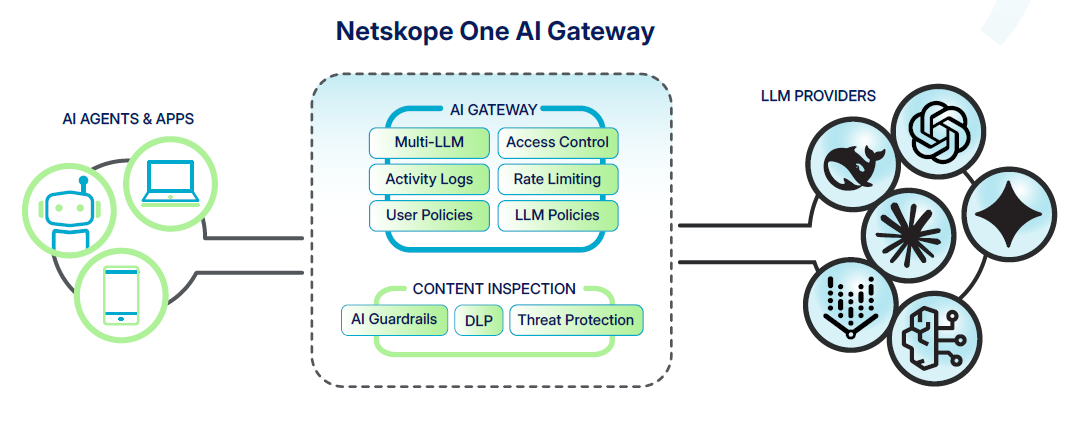
AI Gateway가 제공하는 핵심 기능
Prompt Injection과 Jailbreak를 막는 AI Guardrails
AI Security는 단순 URL 차단이 아니라 사용자의 Prompt와 AI 응답 자체를 분석하는 방향으로 발전하고 있습니다. 공격자는 프롬프트를 조작하여 AI의 시스템 규칙을 우회하거나, 내부 데이터가 포함된 응답을 유도할 수 있습니다.
AI Guardrails는 Prompt Injection, Jailbreak 시도, 민감정보 입력, 소스코드 유출, 유해 콘텐츠 생성 등을 실시간으로 탐지하고 차단합니다.
운영 전 LLM 취약점을 점검하는 AI Red Teaming
내부 LLM과 AI Agent 환경은 운영 전에 Prompt Injection, Jailbreak, 데이터 노출 가능성, 우회 공격 가능성을 검증해야 합니다.
AI Red Teaming은 다수의 공격 시나리오를 기반으로 LLM 보안 취약점을 자동 분석하고, 운영 환경에서 발생할 수 있는 AI 보안 리스크를 사전에 점검하는 접근 방식입니다.
AI Security 도입 시 고려해야 할 사항
NicheTech의 AI Security 접근 방식
NicheTech는 생성형 AI 사용을 단순히 차단하는 방식이 아니라, 기업이 AI를 안전하게 사용할 수 있도록 접근 제어, 데이터 보호, 프롬프트 검사, 감사 로그 기반 운영 체계를 함께 고려합니다.
특히 Netskope AI Gateway, AI Guardrails, DLP, ZTNA 기반 보안 아키텍처를 통해 ChatGPT, Copilot, 내부 LLM, AI Agent 사용 환경을 더 안전하게 운영할 수 있도록 지원합니다.
생성형 AI와 내부 LLM 보안을 함께 고민하고 계신가요?
NicheTech는 AI Gateway, AI Guardrails, DLP, ZTNA 기반의 보안 아키텍처를 통해 기업의 AI 사용 환경을 안전하게 통제하고 운영할 수 있도록 지원합니다.
AI Security 문의하기